Systematic evaluation of CNN advances on the ImageNet
paper: Systematic evaluation of CNN advances on the ImageNet
The paper systematically studies the impact of a range of recent advances in CNN architectures and learning methods on the object categorization (ILSVRC) problem. The evalution tests the influence of the following choices of the architecture:
- non-linearity (ReLU, ELU, maxout, compatability with batch normalization);
- pooling variants (stochastic, max, average, mixed);
- network width;
- classifier design (convolutional, fully-connected, SPP);
- image pre-processing;
- learning parameters: learning rate, batch size, cleanliness of the data.
The paper uses 128x128 pixel images for saving time which is sufficient to make qualitative conclusions about optimal network structure.
Evaluation framework
The commonly used pre-processing includes image rescaling to 256xN, where N ≥ 256, and then cropping a random 224x224
square,but we limit the image size to 144xN where N ≥ 128 (denoted as ImageNet-128px) to save training time. The test parameters and 2x tinner CaffeNet are as follows.
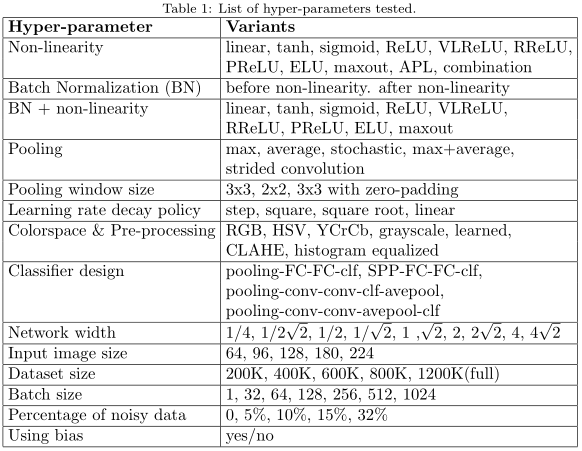
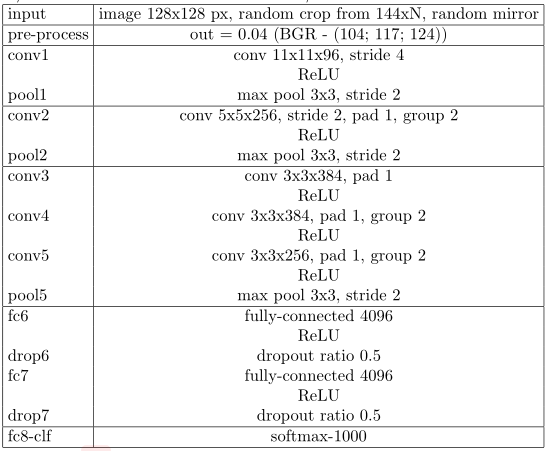
Experiment
Activation functions
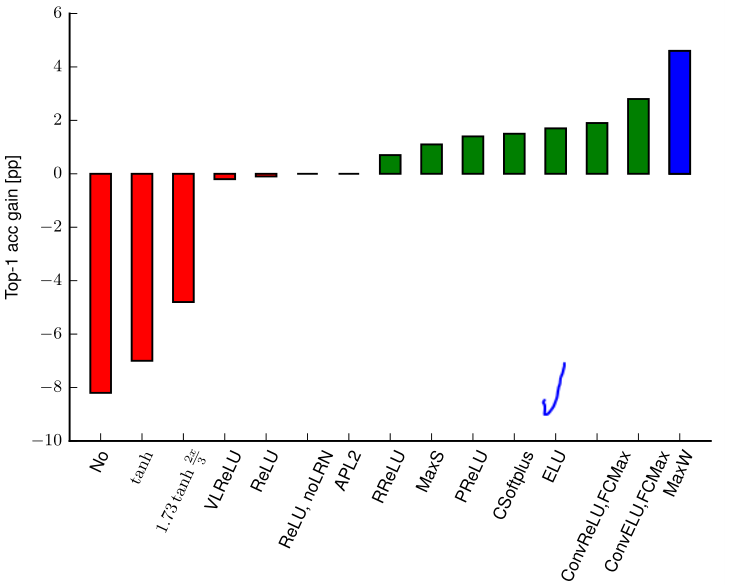
- The best single performing activation function similar in complexity to ReLU is ELU.
- Wide maxout outperforms the rest of the competitors at a higher computational cost.
Pooling

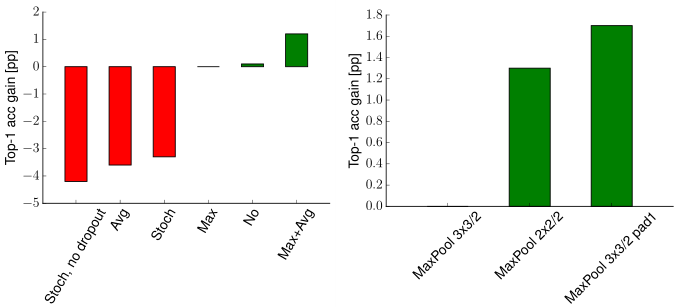
- The best results were obtained by a combination of max and average pooling.
Learning rate policy

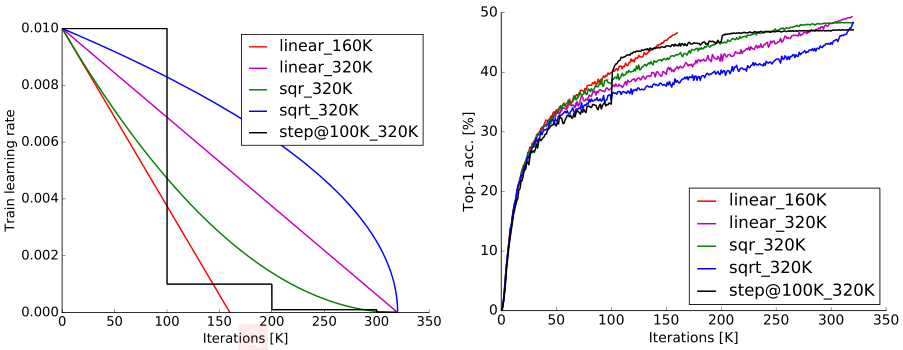
- Learning rate is very important.
- “reduce learning rate 10x, when validation error stops decreasing” is the most commonly used learning rate decay policy, but linear decay gives the best results.
Image pre-processing
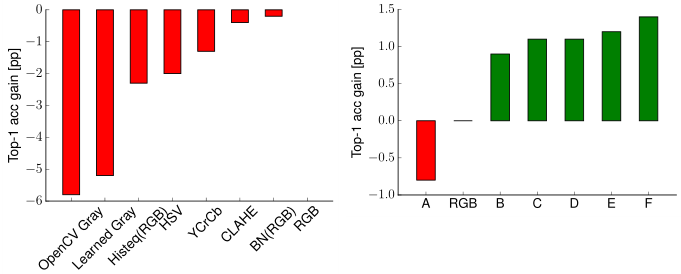
- RGB is the best suitable colorspace for CNNs
- to learn a transformation which can be seen as extending the CaffeNet architecture with several 1x1 convolutions at the input can improve the performance.
Batch normalization
- solve the gradient exploding/vanishing problem and guarantees near-optimal learning regime for the layer following the batch normalized one.
- it works well in CaffeNet and VGG, but not good in GoogLeNet
Classifier design
Batch size and learning rate

- keeping a constant learning rate for different mini-batch sizes has a negative impact on performance.
- large (512 and more) mini-batch sizes leads to quite significant decrease in performance.
Network width
Input image size
Dataset size and noisy labels
Bias in convolution layers
Conclusions
- use ELU non-linearity without batchnorm or ReLU with it.
- apply a learned colorspace transformation of RGB.
- use the linear learning rate decay policy.
- use a sum of the average and max pooling layers.
- use mini-batch size around 128 or 256. If this is too big for your GPU, decrease the learning rate proportionally to the batch size.
- use fully-connected layers as convolutional and average the predictions for the final decision.
- when investing in increasing training set size, check if a plateau has not been reach.
- cleanliness of the data is more important then the size.
- if you cannot increase the input image size, reduce the stride in the consequent layers, it has roughly the same effect.
- if your network has a complex and highly optimized architecture, like e.g. GoogLeNet, be careful with modifications.