segmentation(4) -- DilatedNet、DRN
paper: DilatedNet: MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS | [ code/pytorch_code ]
总体结构
a VGG16 based front-end prediction module + a context module
- 对于front-end: We adapted the VGG-16 network for dense prediction and removed the last two pooling and striding layers. Specifically, each of these pooling and striding layers was removed and convolutions in all subsequent layers were dilated by a factor of 2 for each pooling layer that was ablated.
接下来得到channel为C(类别)的feature map. 通过context module, 得到C channel的输出, 如下所示
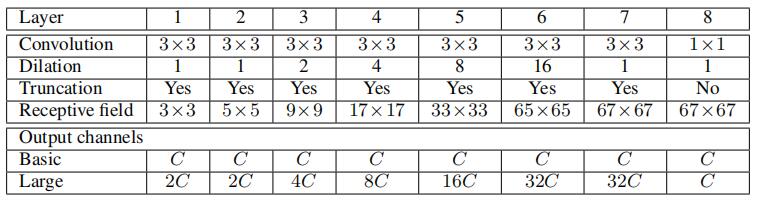
特点
使用dilated convolution. 作者认为Pooling or upsample增加感受野的方式会使得图片分辨率变小,空间信息丢失,而使用dilated convolution可以在不缩减尺寸的情况下增加感受野。
paper: DRN: Dilated Residual Networks | [pytorch_code]
总体结构
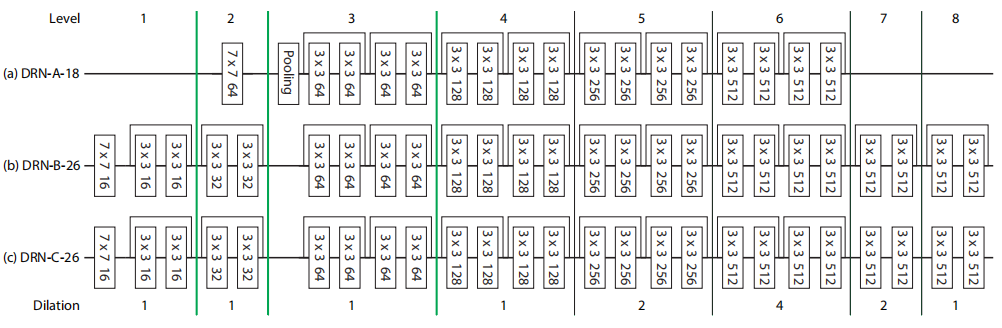
DRN算是DilatedNet的升级版,使用resnet结构代替VGG。并在此再次表明自己的观点:
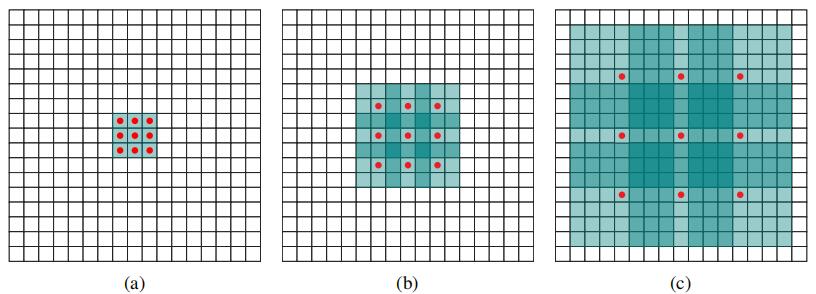
- 考虑到小物体在大背景的情况下,经过多次缩减,the background response may suppress the signal from the object of interest. What’s worse,if the object’s signal is lost due to downsampling, there is little hope to recover it during training.
- 增加输出分辨率最直接的办法就是减少尺寸缩减的次数。但是尺寸缩减次数减少,后层感受野减小,有可能reduce the amount of context that can inform the prediction。
- 考虑到以上两点,又要减少尺寸缩减的次数,提升输出分辨率,又要感受野不变小,就在后面几层使用dilated convolution来提高感受野。
上面DRN-A-18结构就是在resnet18的基础上进行改进。Group4和Group5的residual blocks不使用尺寸缩减,而是使用factor为2和4的dilated convolution。

对于DRN-B-26,because this maxpooling operation leads to high-amplitude high-frequency activations, 所以用了两个resblock来代替,并在最后加了两个resblock来减小输出网格效应,但也一定加深了网络的深度。为了进一步减小网格效应,DRN-C-26将最后加的两个resblock跳跃连接去掉了。

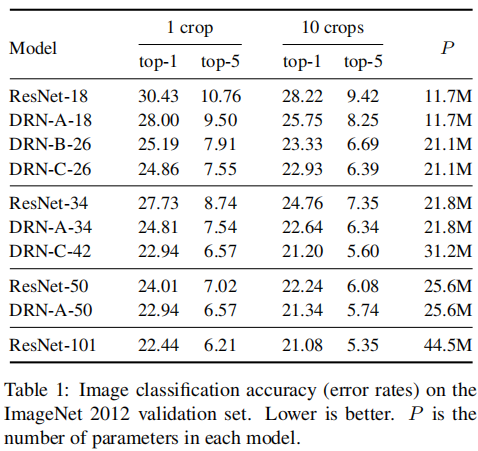
results
Imagenet classification
Cityscapes segmentation
