segmentation(3) -- ENet、LinkNet、FC-DenseNet
paper: ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
总体结构

主要模块如下
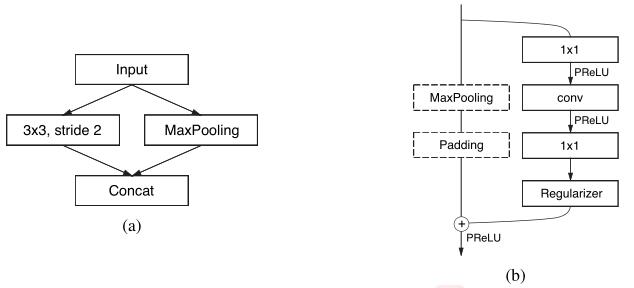
(a)为初始的init
(b)为整体结构主要模块,借鉴resnet中bottleneck,其中
- regularizer use Spatial Dropout, with p = 0.01 before bottleneck2.0, and p = 0.1 afterwards.
- bottleneck downsampling: using maxpooling and replace the first 1x1 projection with a 2x2 conv stride=2
- bottleneck dilated: conv使用空洞卷积
- bottleneck asymmetric: conv使用分离卷积 eg. 5x1conv + 1x5conv
- bottleneck unsampling(decoder): replace maxpooling with max unpooling
特点:
- use dilated convolutions to have a wide receptive field
- early downsampling
- a large encoder and a small decoder
- use PReLUs, not ReLUs
- factorizing filters by using 5x1 conv and 1x5 conv
- regularization update from L2 -> stochastic depth -> Spatial Dropout
paper: LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation [ website | pytorch_code ]
总体结构
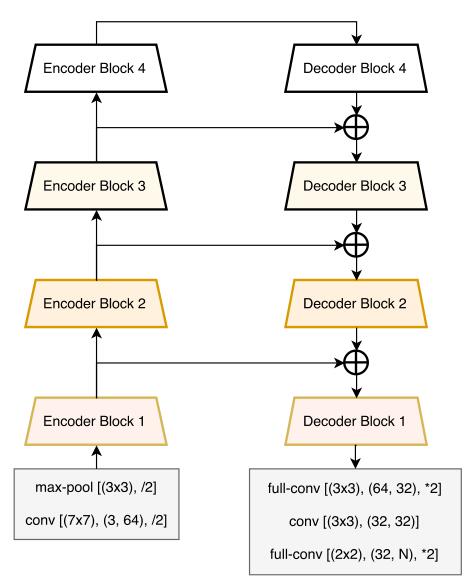
其中encoder block 及 decoder block 分别如下
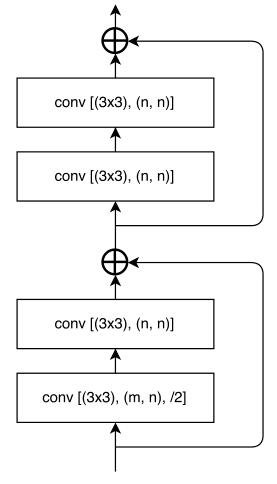

- use ResNet18 as its encoder
- link each encoder with decoder which is aimed to recover lost spatial information
- can give real-time performance even on NVIDIA TX1 embedded system module
- use weighing scheme $w_{\text {class }}=\frac{1}{\ln \left(1.02+p_{\text {class }}\right)}$, which is better than mean average frequency
- use database cityscape and camvid
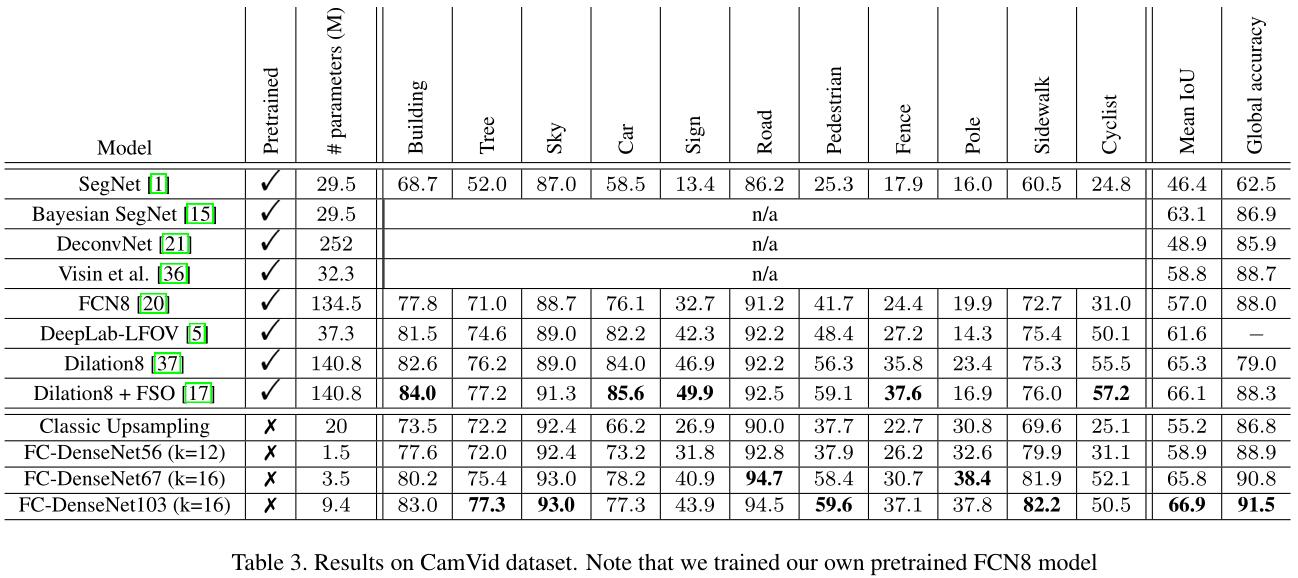
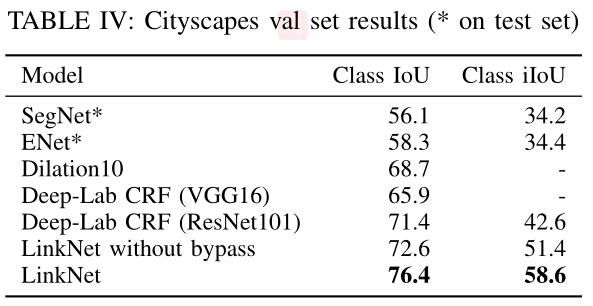
实验结果
- cityscape
- camvid

paper: The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
总体结构
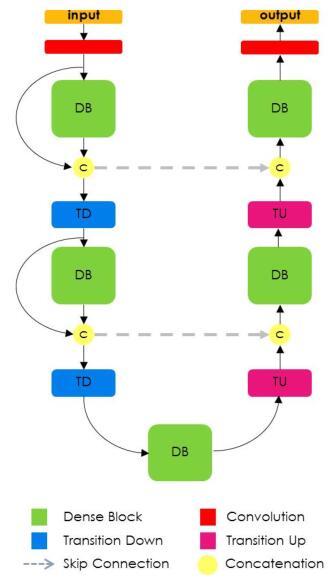

其中DB(Dense Block)、DB中的layer、TD(尺寸缩减)、TU(尺寸变大)部分如下


- use DenseNet architecture
- use database camvid and gatech
实验结果
- camvid