segmentation(2) -- U-Net、SegNet
paper: U-Net: Convolutional Networks for Biomedical Image Segmentation
总体结构
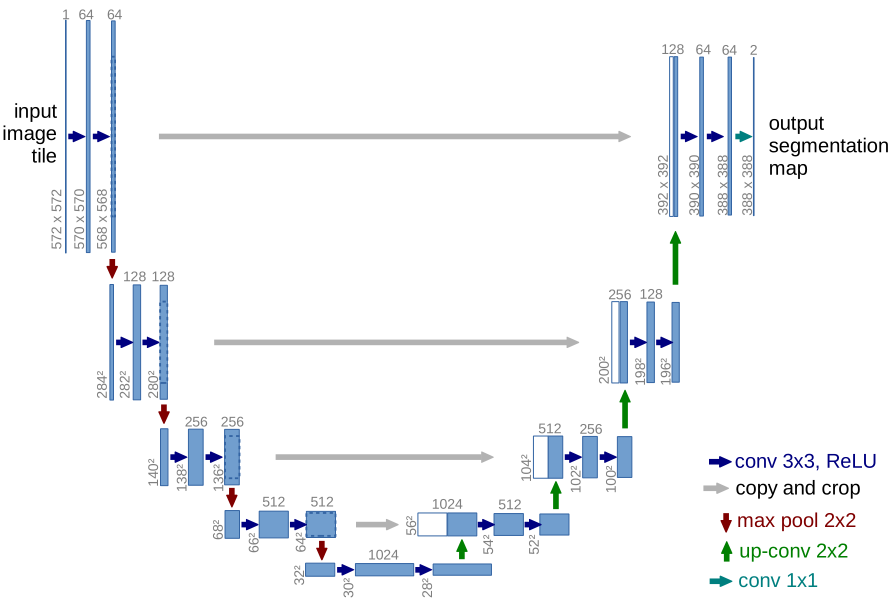
1.输入使用镜像边缘填充。图像大小为512x512,边缘镜像翻转30pixel,则输入图像尺寸变为572x572.
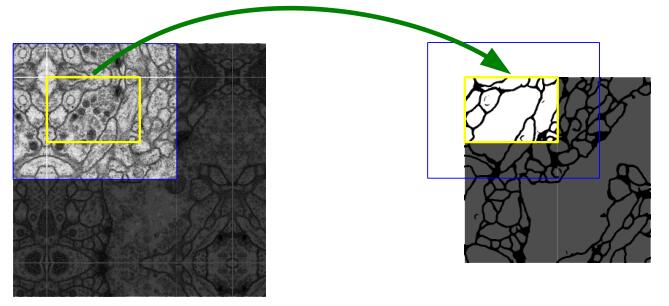
2.网络中的卷积不使用padding,编码部分和解码部分尺寸不对应,特征拼接时需要centercrop。
3.输出为2通道,使用二分类cross entropy。考虑到让网络能学习到紧邻的两个细胞间的边界,每个pixel的loss需要乘以weight map对应的权重。如下图d,紧邻的两个细胞间的边界部分有较高的权重。

$$
E=\sum_{\mathbf{x} \in \Omega} w(\mathbf{x}) \log \left(p_{\ell(\mathbf{x})}(\mathbf{x})\right)
$$
$$
w(\mathbf{x})=w_{c}(\mathbf{x})+w_{0} \cdot \exp \left(-\frac{\left(d_{1}(\mathbf{x})+d_{2}(\mathbf{x})\right)^{2}}{2 \sigma^{2}}\right)
$$
其中$w_{c}$是平衡类别比例的权值,$d_{1}$是像素点到距离其最近的细胞的距离,$d_{2}$是像素点到距离其第二近的细胞的距离。$w_{0}$和l$\delta$是常数值。
paper: SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
总体结构

- 使用encoder-decoder结构,编码部分使用预训练VGG16.
- 编码时需要保存maxpooling的位置信息(每个pixel使用2bit存储信息),供解码时上采样使用。
- 和DecovNet不同的是,Segnet不使用VGG16的全连接层,全连接层包含的大量参数,因此Segnet比DecovNet参数少很多。
- 使用cross-entropy loss,考虑median frequency balancing类别平衡。