segmentation(1) -- FCN、DeconvNet
paper: Fully Convolutional Networks for Semantic Segmentation
总体结构
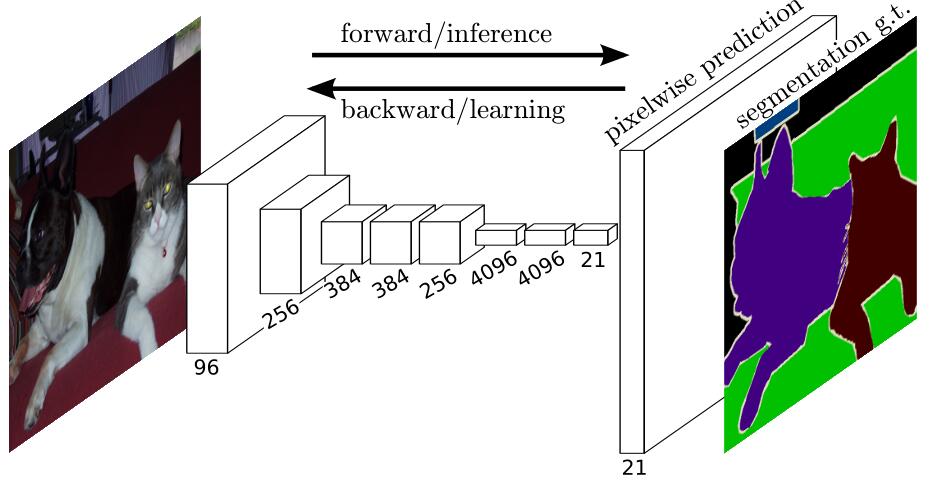
- 首先在语义分割问题中使用end-to-end的CNN model。
- FCN使用pretrained VGG16,将VGG16后面的全连接层用卷积层来代替,因此输入可以是不固定的尺寸。
- 最后所使用的1x1卷积进行分类,输出的channel数为num_calsses+1(背景),本质上是一个像素级别的分类问题。
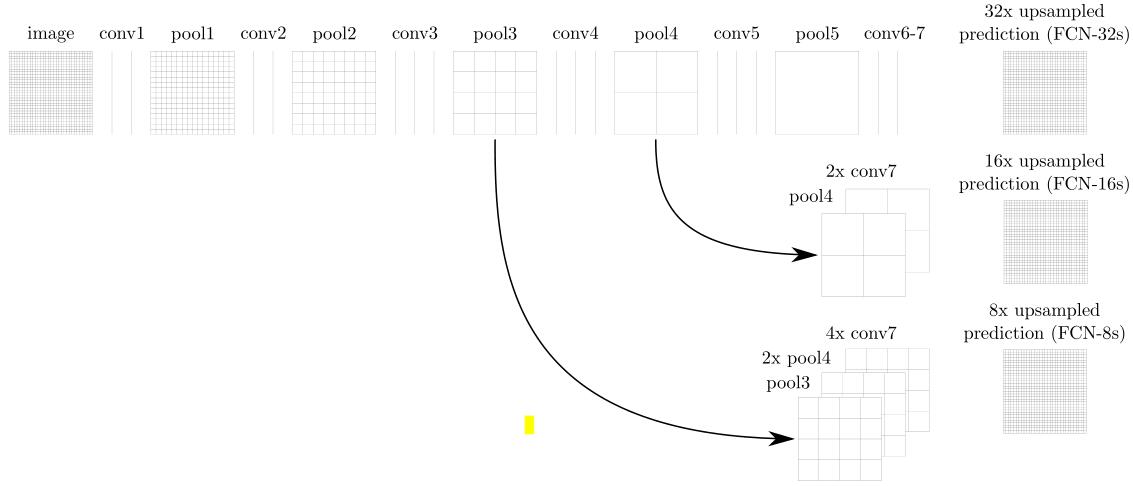
FCN-32s对前面预测出的结果直接Upsample到输入图像大小
1
2conv7 = conv7_classifier(conv7)
output = 32xUpsample(conv7) #得到原图大小的outputFCN-16s使用skip connection融合conv7和pool4的结果。
1
2
3
4conv7 = conv7_classifier(conv7)
conv7 = 2xUpsample(conv7)
pool4 = pool4_classifier(pool4)
output = 16xUpsample(conv7+pool4) #得到原图大小的outputFCN-8s使用类似的连接
1
2
3
4
5
6conv7 = conv7_classifier(conv7)
conv7 = 4xUpsample(conv7)
pool4 = pool4_classifier(pool4)
pool4 = 2xUpsample(pool4)
pool3 = pool3_classifier(pool3)
output = 8xUpsample(conv7+pool4+pool3) #得到原图大小的output上述中Upsample也可以使用转置卷积,有可以学习的参数。
缺点
- 分类结果还不够精细
- 没有考虑物体与物体之间的空间特征
paper: Learning Deconvolution Network for Semantic Segmentation
总体结构
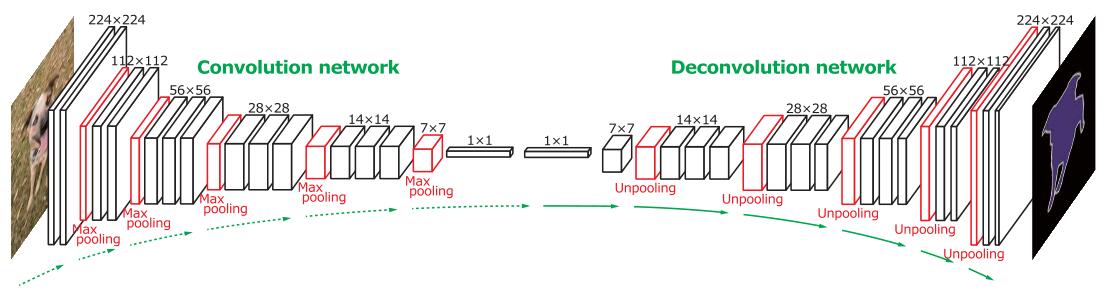
编码部分:
- 使用VGG16结构,包括全连接层,这样训练就包括了全连接层的很多参数。
- 需要记录MaxPooling中的位置信息,供解码部分使用

解码部分:
- Unpooling的位置信息使用对称的Maxpooling中记录的位置信息
- 使用Unpooling+Deconvolution的组合(这也是本文的创新点)