SqueezeNet
paper: SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE with pytorch code
Why we need smaller CNN architectures?
- More efficient distributed training;
- Less overhead when exporting new models to clients;
- Feasible FPGA and embedded deployment.
SqueezeNet achieves AlexNet-level accuracy on ImageNet with 50x fewer parameters. Additionally, with model compression techniques, it is able to compress SqueezeNet to less than 0.5MB (510× smaller than AlexNet).
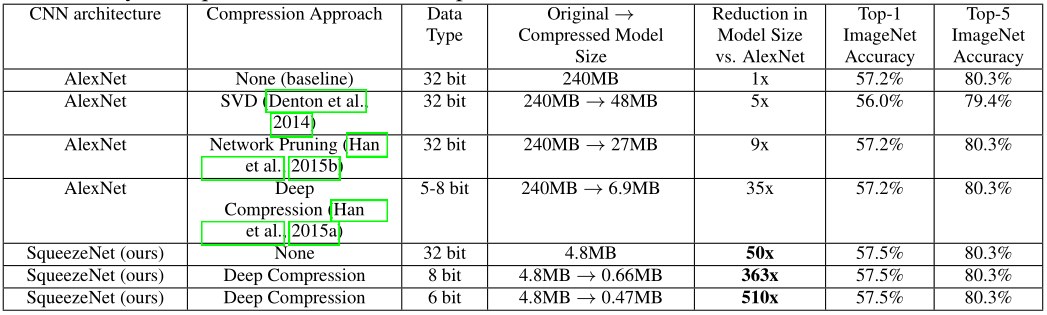
Fire module
1 | class Fire(nn.Module): |
Architecture
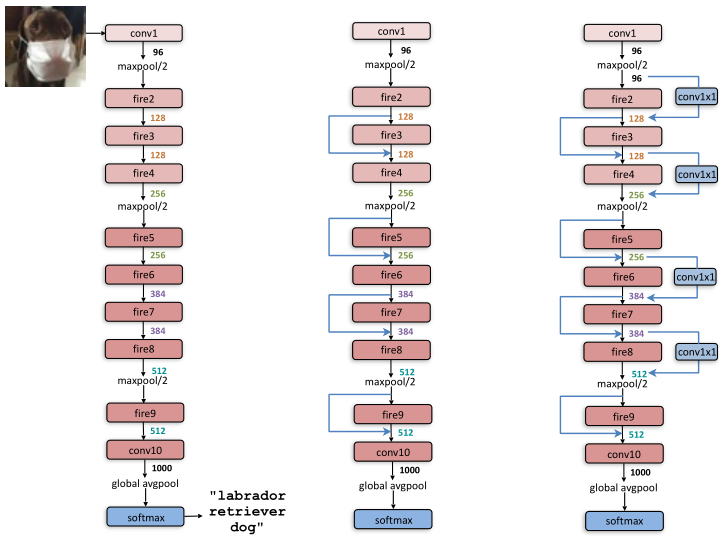
It was designed follow three main strategies:
- Replace 3x3 filters with 1x1 filters (Fire module);
- Decrease the number of input channels to 3x3 filters (Fire module);
- Downsample late in the network so that convolution layers have large activation maps