SKNet
paper: Selective Kernel Networks
It is well-known in the neuroscience community that the receptive field size of visual cortical neurons are modulated by the stimulus, which has been rarely considered in constructing CNNs. In Selective Kernel (SK) unit, multiple branches with different kernel sizes are fused using softmax attention that is guided by the information in these branches.
Selective Kernel Convolution
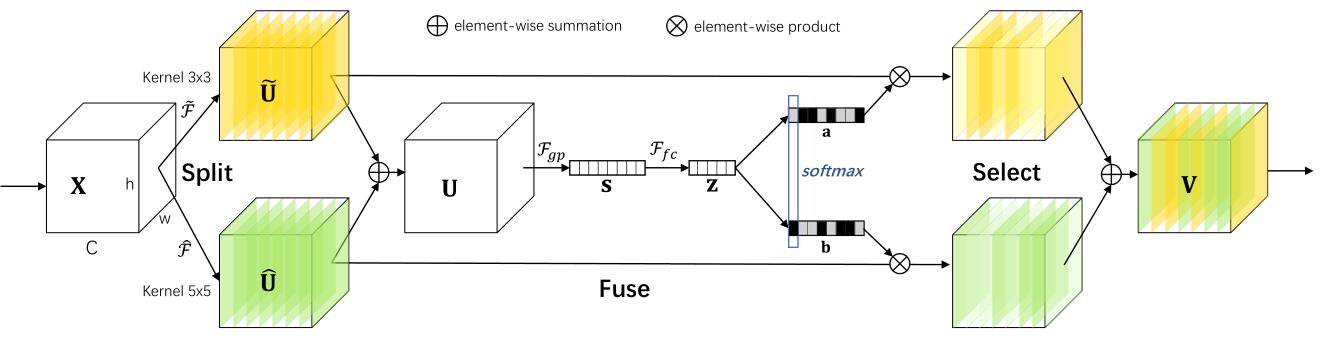
SKNet is inspired by Inceptions using different RFs(receptive fields), but it can adaptively adjusting their receptive field sizes according to the input because of sk convolution. 3 steps for are as follows:
- split: conduct different transforms(diff RFs) to the given feature map. picture shows the sk convolution with two different kernel sizes 3x3 and 5x5, but it is easy to extend to multiple branches case. For further efficiency, 5x5 conv is repleced with 3x3 conv and dilation size 2.
- fusion: use gates to control the information flows from multiple branches carrying different scales of information into neurons in the next layer. operations are 1) fuse results from multiple branches via an element-wise summation; 2) global average pooling; 3) fc,BN,ReLU from C dimention to d.
- select: use channel-wise softmax operator to select channels from each side. The same as using C softmax layers with M catogories, which also means how many different RFs in split.
Architecture && Training details
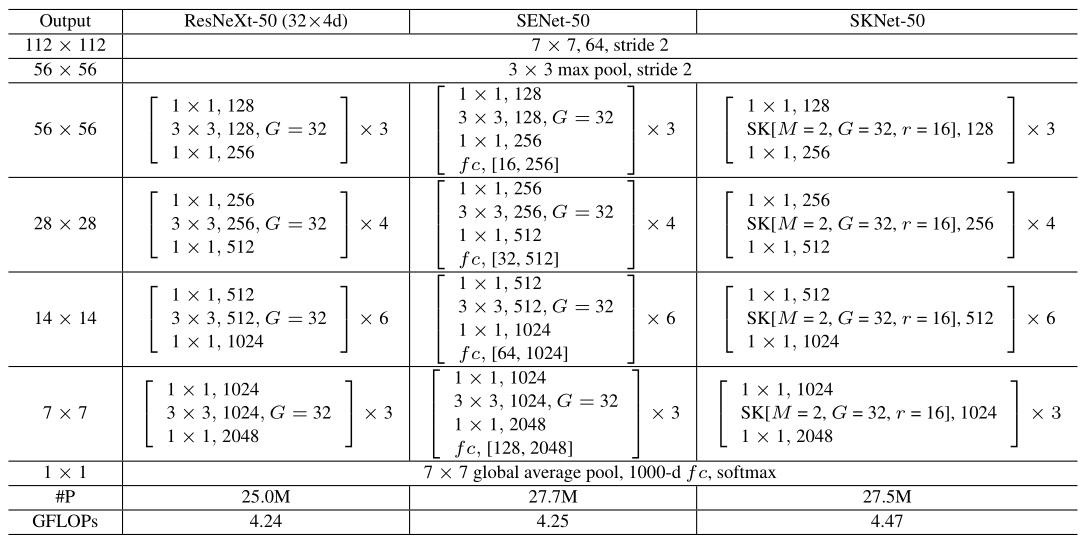
The architecture of the SKNet-50 is above. In general, all the large kernel convolutions in the original bottleneck blocks in ResNeXt are replaced by the SK convolutions, enabling the network to choose appropriate RF sizes in an adaptive manner. Three hyper-parameters are: 1) paths M, which also means how many different RFs in split; 2) group number G used in split; 3) reduction ratio r which control dimention d in fusion. More details are in the paper.
training details for large model:
- SGD with momentum 0.9, a mini-batch size of 256 and a weight decay of 1e-4.
- The initial learning rate is set to 0.1 and decreased by a factor of 10 every 30 epochs.
- All models are trained for 100 epochs from scratch on 8 GPUs, using the weight initialization strategy in He’s.
for lightweight model:
- set weight decay to 4e-5
- slightly less aggressive scale augmentation for data preprocessing
- similar modifications in MobileNet and ShuffleNet
Discussion
- paths M increase, recognition error decrease; while improve from M=2(3x3 + 3x3 with dilation2) to M=3(3x3 + 3x3 with dilation 2 + 3x3 with dilation 3), the top-1 error decreases from 20.79% to 20.76%, so M=2 is better.
- The larger the target object is, the more attention will be assigned to larger kernels by the Selective Kernel mechanism in low and middle level stages. However, at much higher layers, all scale information is getting lost and such a pattern disappears.